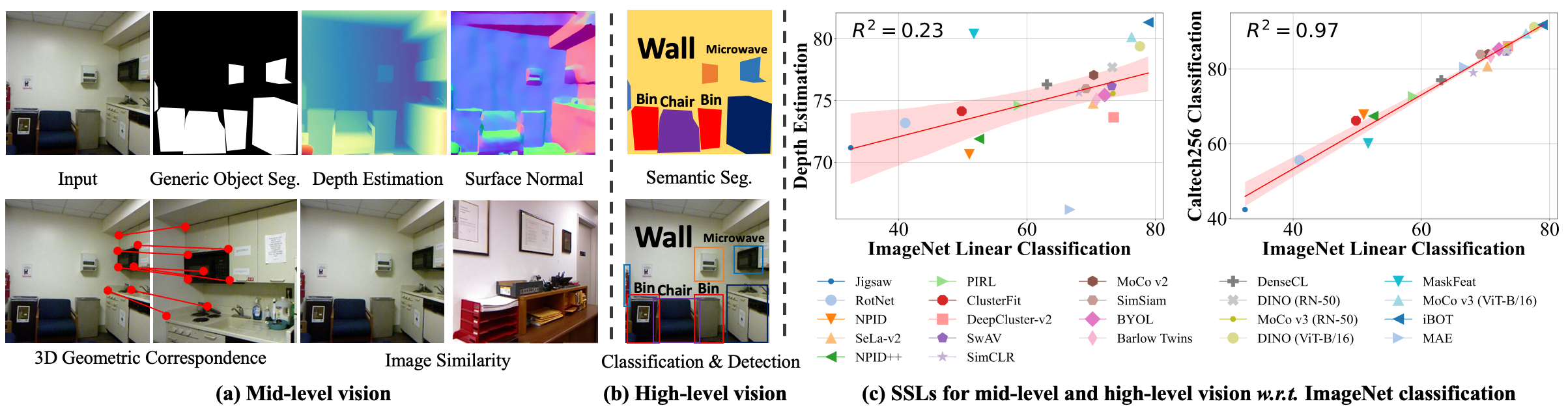
Mid-Level Vision vs. High-Level Vision Tasks.
We provide a comprehensive evaluation of prominent self-supervised learning methods (SSLs) across a wide range of mid-level vision tasks (a), complementing the standard evaluation in high-level vision tasks (b). Although SSL performance in mid-level vision tasks (e.g., depth estimation) is positively correlated with ImageNet linear probing (c, left), this correlation is much weaker than that observed among high-level vision tasks (e.g., Caltech-256 vs. ImageNet classification) (c, right), as indicated by the R2 statistics.
TL;DR: We benchmark 22 SSL models across 8 mid-level vision tasks, showing that strong performance on high-level tasks does not necessarily translate to strong mid-level vision capabilities. we hope our findings guide future SSL research to benchmark models not only on high-level vision tasks but on mid-level as well.
Abstract
Mid-level vision capabilities - such as generic object localization and 3D geometric understanding - are not only fundamental to human vision but are also crucial for many real-world applications of computer vision. These abilities emerge with minimal supervision during the early stages of human visual development. Despite their significance, current self-supervised learning (SSL) approaches are primarily designed and evaluated for high-level recognition tasks, leaving their mid-level vision capabilities largely unexamined. In this study, we introduce a suite of benchmark protocols to systematically assess mid-level vision capabilities and present a comprehensive, controlled evaluation of 22 prominent SSL models across 8 mid-level vision tasks. Our experiments reveal a weak correlation between mid-level and high-level task performance. We also identify several SSL methods with highly imbalanced performance across mid-level and high-level capabilities, as well as some that excel in both. Additionally, we investigate key factors contributing to mid-level vision performance, such as pretraining objectives and network architectures. Our study provides a holistic and timely view of what SSL models have learned, complementing existing research that primarily focuses on high-level vision tasks. We hope our findings guide future SSL research to benchmark models not only on high-level vision tasks but on mid-level as well.
Mid-Level Vision v.s. ImageNet Linear Probing.
High-level vision performance, as measured by ImageNet (IN1k) probing, shows a positive correlation with mid-level vision tasks. This suggests that self-supervised learning (SSL) models excelling in high-level tasks often generate representations that benefit spatial and structural mid-level tasks.
Task-Specific Highlights:
- Generic Object Segmentation: The strongest correlation with high-level tasks (
R2 = 0.70), indicating high-level features effectively capture spatial structures. - Mid-Level Image Similarity: Also highly correlated, showing that high-level representations retain invariance to mid-level variations like viewpoint changes.
- 3D Geometric Understanding: Tasks like surface normal estimation rely on mid-level vision cues, which are often overlooked by high-level feature extraction.
These insights reveal a nuanced relationship between high-level and mid-level vision capabilities, with varying degrees of task-specific correlation.
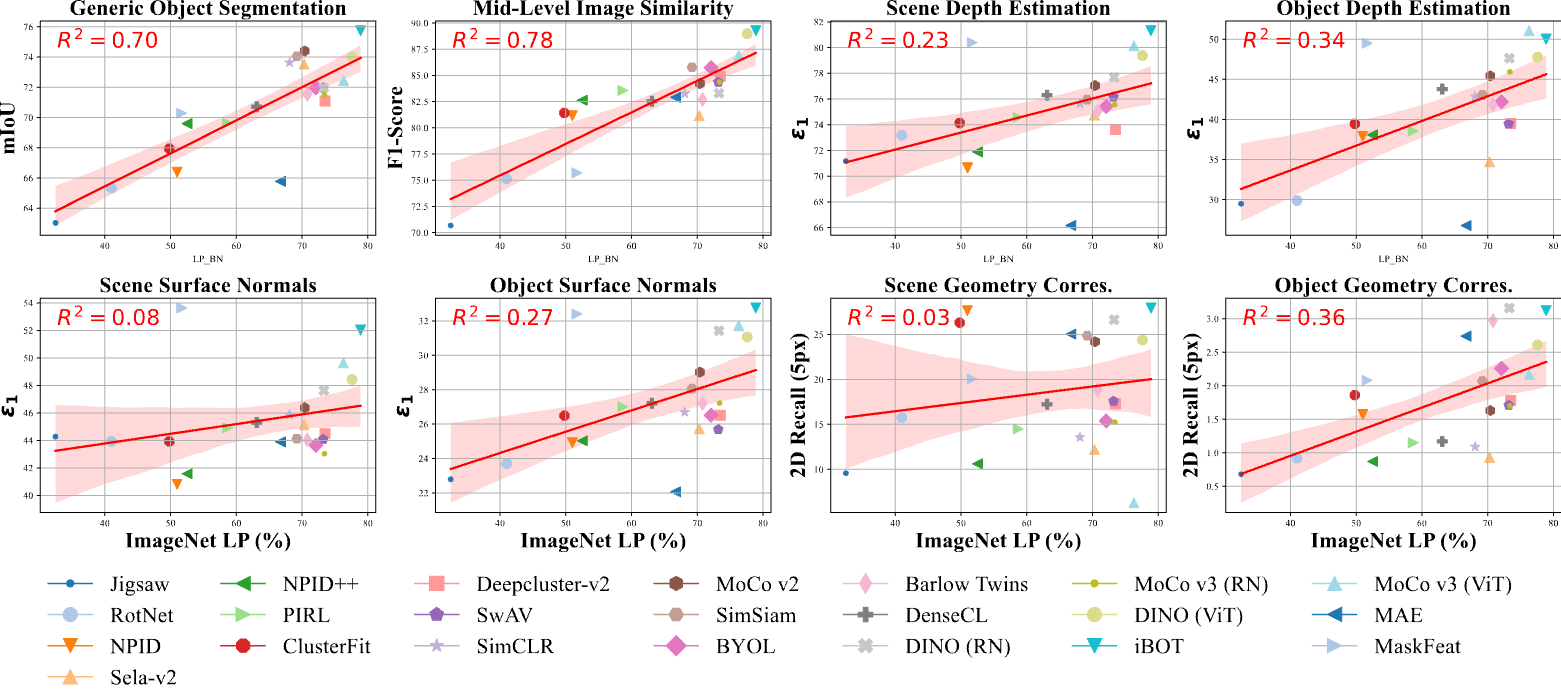
Figure 1. Mid-Level Vision v.s. ImageNet Linear Probing.
We report the performance of self-supervised learning methods on mid-level vision tasks (y-axis) against their ImageNet 1K linear classification accuracy. Metrics are detailed in paper. Linear regression shows correlation with R2 in each plot's top-left corner, and the red shaded area marks the 95% confidence interval.
Does Strong High-Level Performance Imply Strong Mid-Level Performance?
High-level performance often translates to better mid-level vision task performance, as shown in Figure 1 above. SSL models with strong high-level capabilities tend to offer better representations for mid-level tasks, leveraging spatial and structural information.
Correlation Between Tasks
Mid-level tasks such as object segmentation correlate highly with high-level tasks (\(R^2 = 0.70\)), indicating that spatial structures are well captured. Similarly, mid-level image similarity benefits from high-level invariance to variations. However, 3D geometric tasks like surface normal estimation show weaker correlations, as they require finer geometric cues not emphasized in high-level SSL objectives.
We observe with Figure 2 that Object segmentation strongly correlates with mid-level image similarity and depth estimation, highlighting the importance of spatial understanding. However, scene geometry correspondence shows weaker relationships with other tasks, emphasizing its unique requirements.
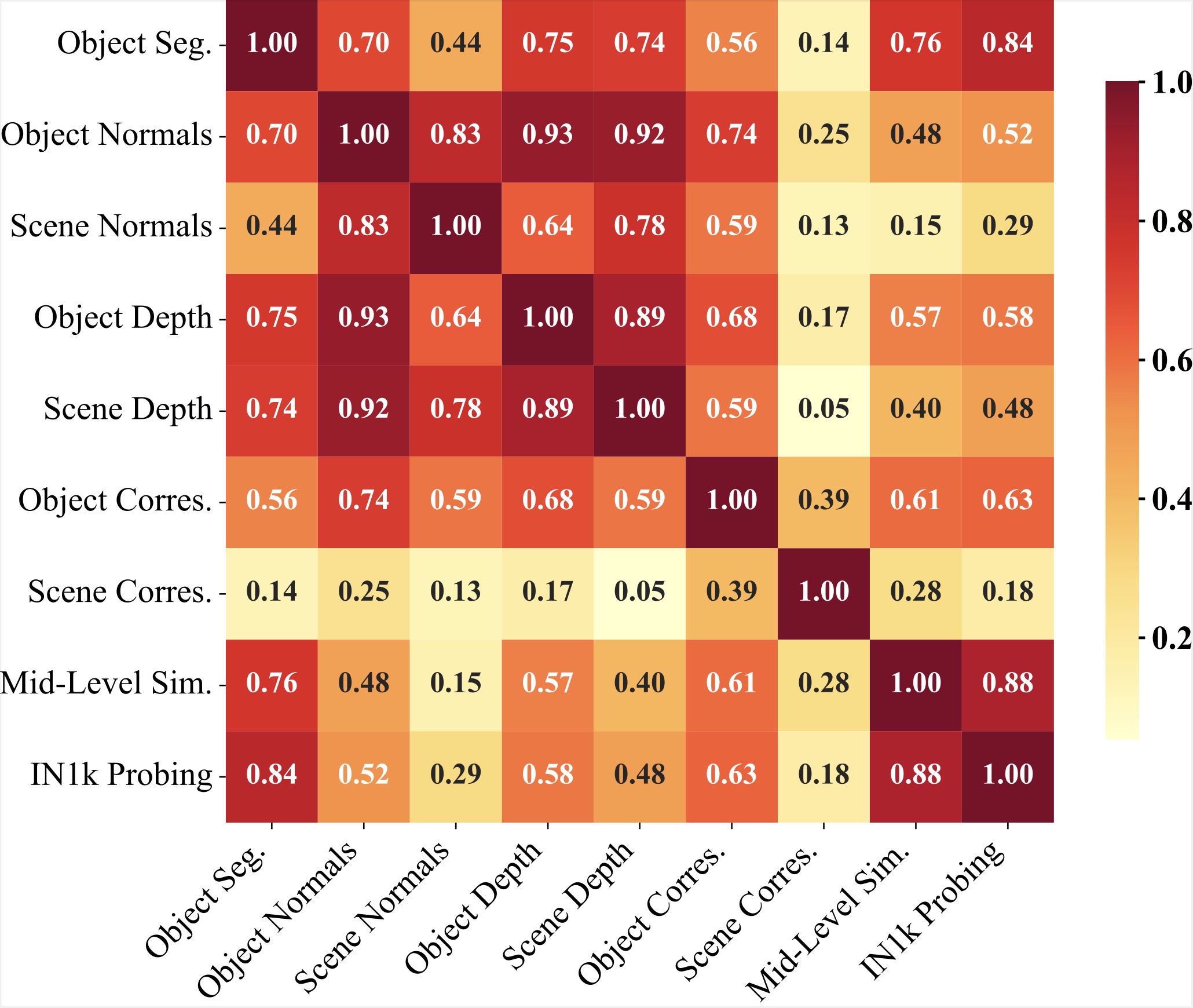
Figure 2. Correlation coefficients across mid-level vision tasks.
Ranking of SSL Models
Figure 3. compares SSL models based on mid-level and high-level performance. Some models excel in high-level tasks but lag in mid-level capabilities. MaskFeat stands out with exceptional mid-level performance, while MAE struggles with finer details. iBOT and DINO rank among the top performers, while earlier methods like RotNet and Jigsaw fall behind.

Figure 3. SSL model ranking based on mid-level and high-level tasks.
Additional Visualizations
We present qualitative visualizations below to assess model performance on mid-level vision tasks. These visualizations validate the models' ability to learn and perform each mid level vision task effectively.
Citation
@article{chen2024probingmidlevelvisioncapabilities,
title={Probing the Mid-level Vision Capabilities of Self-Supervised Learning},
author={Xuweiyi Chen and Markus Marks and Zezhou Cheng},
year={2024},
eprint={2411.17474},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.17474},
}